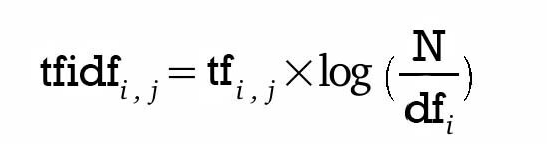
단어들 중에서 더 중요한 단어가 존재할 경우 tf - idf vector 사용
(순서는 고려하지 않음)
어떤 문서에나 자주 나오는 단어 => 관사, 대명사
특정 문서에서 자주 나오는 단어 => related to Topic
tf - idf score = tf X log( N / df )
tf ( term frequency ) : 현재 문서에서의 빈도수
df ( document frequency ) : 이 단어가 나오는 문서의 총 개수
* tf - idf vecter : BoW vector 에서 tf 점수를 idf 로 normalize *
'머신러닝 > NLP' 카테고리의 다른 글
| Cosine Similarity (코사인 유사도) (0) | 2024.05.16 |
|---|---|
| 단어의 표현 방법 (0) | 2024.05.14 |
| LM ( 언어모델 ) (0) | 2024.05.14 |
| 데이터 분리 (0) | 2024.05.14 |
| Keras(케라스)의 텍스트 전처리 (0) | 2024.05.14 |



